Machine Learning on Corda
June 19, 2020
By Jonathan Scialpi, Solutions Engineer at R3
Decentralized Corpus Manager

Table of Contents
- Introduction
- The Issues
- The Solution
- Advantages of Corda
- Further Work & Utilization
- Conclusion
- Resources
Introduction
We often hear about innovative ways that machine learning models are leveraged in applications. What we almost never hear of how painful is the experience that the data scientists who create these models go through. In this article I will discuss (assuming you have a basic understanding of Corda):
- What common issues data scientists face when trying to build these models
- How I solved these issues with a CorDapp called Decentralized Corpus Manager.
- Why Corda is the right choice for decentralized machine learning applications
Before we dive into the issues, let’s briefly cover some common terms and the overall workflow to produce a machine learning model. Since machine learning is a rather vast subject with many specializations, let’s focus specifically on text classification. The goal of text classification is simply to categorize a piece of text. A few common use cases for text classification are sentiment analysis, spam detectors, and intent detection.
Teaching a machine how to classify text is analogous to how you would teach a child how to detect objects that are colored “red” and those that are “not red”. You would compile a set of photos which contain red items like an apple or a fire truck and another set of items that are not red like a banana or a tree. Then you would simply show each picture to the child and categorize it aloud.
To teach a machine how to classify with accuracy, data scientists compile a data set (known as a “corpus”) with various sample texts (called “utterances”) along with their respective classification category (“labels”). This corpus will be fed to a classification algorithm which will tokenize the corpus and produce a model. This model is what the machine references when trying to make predictions.
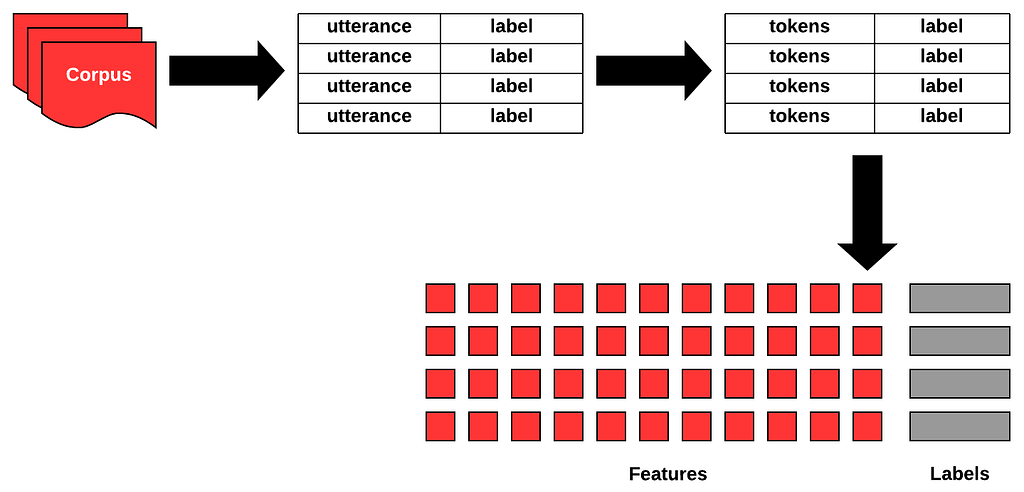
The Issues
Good, clean data can be hard to find:
There are four main ways to acquire training data and each has their own issues:
- Data sharing sites like Kaggle:
These sites are great for getting started in machine learning but most of the time will not have the data that you are looking for, since every classification model is unique to its use case. For example, let’s say you are building an intent detection application capable of determining whether someone was asking to reset their password or not (the not label is commonly referred to as the “negative” category) from within a mobile banking application. You go to Kaggle, download the data, train your model and test it out to notice that your model has 60% accuracy score as utterances such as “I can’t get into my USA banking mobile app!” are failing because the data set you downloaded contained generalized utterances such as “I lost my excel document containing all of my credentials…”. Generalizations like this could cause models to overfit or underfit.
- Client data:
If you’re [un]lucky (depends how you look at it), the client who you are creating a classification model for will tell you that they have heaps of data that you could use to train the model only to find out that the “heaps of data” are really just unstructured exports of help desk incident tickets where people are trying to access their account. This, of course, means that you must manually sift through these logs. You could make some regex-based script to speed up the process but you will eventually still have to sift and structure the data according to your training needs.
- Manual creation:
If you want something done right, do it yourself…right? Besides the fact that you’d probably rather be spending your time on something else besides writing utterance after utterance, just writing the corpus yourself can result in a biased data set where you have imposed conscious or unconscious preference that may go undetected until your app hits production.
- Crowdsourcing data:
You can use sites like Mechanical Turk to offer a five-cent bounty for every utterance that is related to an intent you’re classifying. For a low price, this can relieve you of the burden from having to type up your own utterances but there is still no guarantee that people will follow your instructions perfectly and you will be stuck manually reviewing each utterance that was submitted.
Data corruption:
Besides underfitting, overfitting, structure, bias, and time lost in review, data can also become corrupted. One human error in reviewing a pull request on a corpus can have disastrous effects on a model’s performance. Even online training solutions where models are learning from live data or batched data can become corrupted by a bug in data ingestion or filtering can render a model/application useless.
The Solution
Based on my experience with the above issues, I believe that the crowdsourcing approach is the most practical. It gives the best chance at avoiding bias while also relieving the burden of creating a corpus from scratch. However, the problems of underfitting/overfitting, manual review, and manual corpus maintenance still exist. If only there was an automated way to ensure crowdsourced contributions follow my format and only accept these contributions if they have a positive effect on the model’s performance…
Introducing the Decentralized Corpus Manager! DCM is an application I built to facilitate data crowdsourcing for machine learning models using Corda. Beyond crowdsourcing, Corda contracts provide a way to tackle the three remaining problems:
- Enforce a standard way to propose corpus contributions to avoid manual reviews.
- Only commit changes to a corpus if it improves the model’s performance to avoid manual corpus maintenance.
- Accomplish 1 & 2 in an automatic/programmatic way that is cryptographically secure.
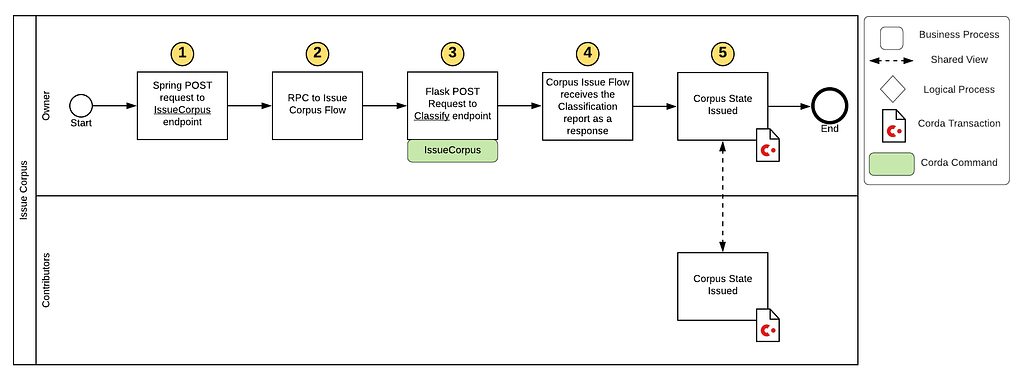
How to Issue a Corpus:
Step 1 — The user issuing the corpus (known as the “owner”) can call the IssueCorpus REST API to create a CorpusState.
Step 2 — Once the issueCorpus Spring endpoint is called and starts the IssueCorpusFlow via RPC.
Step 3 — The flow makes an external POST request to the Flask server which consumes the corpus. The utterances and their respective labels are then used to build a model and are measured against a test set.
Step 4 — The results of the test set are passed back to the IssueCorpusFlow as a JSON response to be included as the classificationReport attribute on the CorpusState.
Step 5 — Lastly, all participants sign and verify the new state and their ledgers are updated with the new CorpusState.
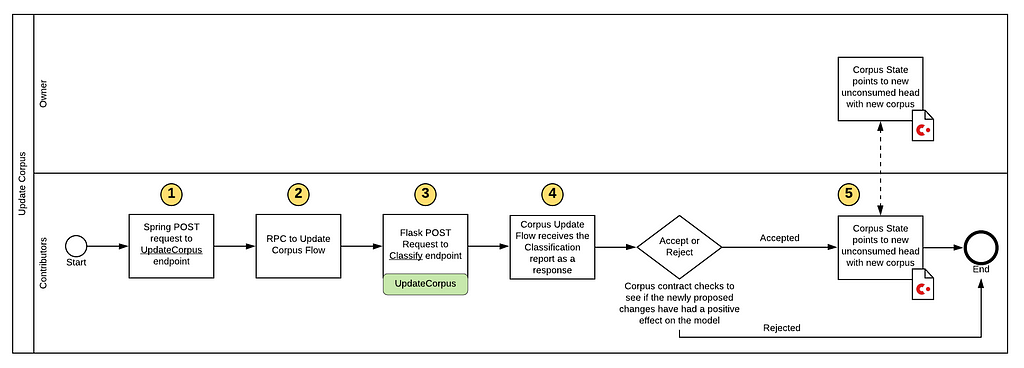
How to Update a Corpus:
Steps 1–5 for the corpus update are like that of the issuance. The major difference is the command used and its associated requirements in the smart contract:
- Line 7 protects against the removal or addition of any new labels which would ruin the shape of our model.
- Line 14 ensures that an update to a corpus will only be considered a valid transaction if there is a positive delta between the classification report found in the input state (current) and the one found in the output state (proposed).
Advantages of Corda
Now that I have proven that blockchain can be used to solve the issues that come with producing machine learning models, let’s examine why Corda is the right blockchain platform for this use case by drawing comparisons from Microsoft’s Decentralized & Collaborative AI on Blockchain (I will refer to this framework as DeCA). This framework is built on the Ethereum platform to host and train publicly available machine learning models.
Storage Costs
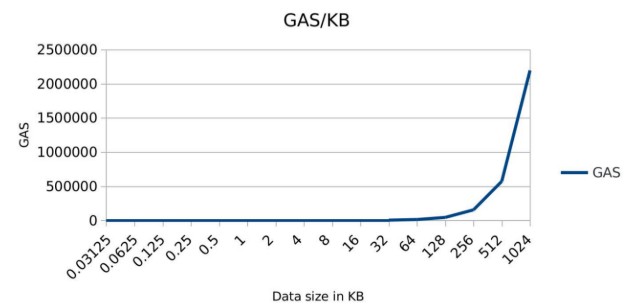
While both DCM and DeCA store data and meta-data relative to the model in progress on-chain, it’s important to distinguish how the term “on-chain” affects the cost outcome. Being that DCM uses Corda, said data can be stored for low-cost on a cloud database such as Azure’s PostgreSQL. DeCA on the other hand stores its data on the Ethereum blockchain which has extremely high costs.

As demonstrated by the table above, a 1GB write to the ETH blockchain could costs millions making DeCA unusable. To work around the storage cost issue, DeCA only allows contributors to propose one data sample at a time to minimize write fees: “As of July 2019, it costs about USD0.25 to update the model on Ethereum”. It is further explained that this fee could be removed for contributors through a reimbursement.
There are four drawbacks with this approach:
- Restricting the contributions to one data sample at a time will increase the number of transactions necessary to complete the crowdsourcing of a model. Whereas in DCM a contribution can contain any number of the data sample (doesn’t have to be just additional data either, it could contain data deletions) potentially completing the model in one transaction.
- Although each individual transaction might be as low as USD0.25 and seem insignificant, if you add up the total fees of each individual transaction, the total cost will still be way higher than the cost of PostgreSQL db. It just seems lower from the individual contributor’s perspective.
- While contribution fees could potentially be reimbursed for the contributor, the individual who is reimbursing the contributor will still have to assume the cost of network computation. This cost can potentially be offset somewhat by fees consumed by bad contributions if using a staking incentive mechanism but would mostly fall on the individual responsible for reimbursements.
- Another drawback of using an Ethereum based solution is on the initial issuance or creation of the model. According to Microsoft’s blog post, “Hosting a model on a public blockchain requires an initial one-time fee for deployment, usually a few dollars.” This is probably true but is only a few dollars because there is almost no data in the initial model as the whole purpose is to crowdsource the model. But what if you already have some data to start with and only see to partially crowdsource the rest of the model? This would require more computation from the Ethereum Virtual Machine and as a result, will have an exponential impact on the cost of initial deployment.
Privacy
Due to the nature of the gossip protocol, every transaction that is made through DeCA will be seen throughout the network. This includes the proposed corpus contributions, the corpus itself (say goodbye to your “secret sauce”), and any rewards/punishments from its incentive mechanism.
Whereas transactions through DCM are sent as point-to-point messages and sends them only on a need to know basis (lazy propagation). Subjective transactions open the door modifications to how DCM currently works:
- Private contributions: Only the owner and the contributor would be included on a corpus update. The only time the rest of the crowd would see the contribution would be when they received an updated corpus, but they still wouldn’t know who the participant was who made the update.
- Private corpus: Contributors can still propose corpus updates without having access to the corpus. In this case, the “secret sauce” of the model can be preserved while still crowdsourcing data. This can be accomplished by having two separate states. The first state would be for the contribution (which can be between just the owner and contributor, or the contributor and the rest of the crowd) and the second state would be for the corpus itself (which only the owner would be a participant on).
These two modifications are especially interesting since the idea of multiple states doesn’t exist on Ethereum being that its blockchain represents one global state. The only way for DeCA to keep the model private while still accepting contributions would be to store the model off-chain. In contrast, the privacy modifications for DCM would still store both the contribution and the model on-chain!
Decentralization
Although lazy propagation allows for private transactions, the drawback is obviously in decentralization when compared to the gossip protocol. Being built on Ethereum, DeCA by default will send every transaction to every node on the network allowing any node to participate. Although DCM doesn’t include every node on the network by default in every transaction, my current implementation doesn’t prevent any node from being a contributor. Meaning, any participant included within a corpus state can add any other participant on the network. Furthermore, if you had a list of every participant on the network you could technically include each one of them on a corpus state issuance.
Thus, participation in DCM is by default semi-decentralized with the potential to be fully decentralized. Contributions are still decentralized between those that are included on the state since any of those participants can propose state changes.
Further Work & Utilization
Incentive Mechanisms
To ensure participation in a crowdsourcing application, building an incentive mechanism is vital. Although my first goal was to prove that this functionality was possible on Corda, I built it knowing that the incentive mechanism would probably be the next task in the pipeline. With the delta variable mentioned earlier (in the Corpus Contribution Flow section), there is a way to tell if a user’s contribution had a positive/negative effect on the model’s performance and measure how much it improved/degraded by. Using this measurement, a payout scheme can be implemented such as DeCA’s staking approach or something more rudimentary such as: for each positive delta point, the owner of the model pays out X amount of DCM tokens that were used to fund the crowdsourcing project.
Model Storage
DCM currently stores the corpus that is used to produce a model and its respective metadata but does not actually store the model object. I don’t think this would be difficult to accomplish and could add some value to the CorDapp being that it allows for more flexibility. For example, you might have a corpus state which contains data you wish to keep private but would like to sell subscriptions to other participants willing to pay some fee to use your model’s classification.
Corpus Trading
The storage of a corpus and its respective model on-chain opens the door for the sharing of these data sets for the common good or to make a profit.
- Common good example: A consortium of banks who pool a data set of fraudulent transactions to make a fraud detection model capable of classifying whether a credit card purchase should be flagged or not.
- Profit example: Some hedge fund creates a regression model which could be sold as a subscription, one-time purchase, or simply traded in exchange for access to some other hedge fund’s model. The data could also be sold or traded separately from the model.
Oracles
DCM currently uses a FlowExternalOperation to make a POST request to the Flask server endpoint which responds back with the classification report. Instead, I’d like to examine Corda Oracles to see how their usage could benefit the CorDapp. An immediate benefit I can think of is that the Oracle is a permissioned node on your network and therefore you can trust the response you receive back from the classification endpoint if you see the Oracle’s signature on the request/transaction.
Training Set Selection
Thirty per cent of the training data submitted is randomly selected and used to test the classification model’s performance and produce a classification report. Being that it is random, the smaller the data set is, the greater the chance that new data added to the corpus might end up in the testing set rather than the training set. The flask API should be altered to only consider data that is outside of the contribution set to guarantee that it is used to train the model rather than test it.
Conclusion
The power in crowdsourcing is manifested in the development of machine learning models. Whether it’s for classification, regression, or clustering, machine learning models are only as good as the data that supports them. Blockchain technology protects said data with a distributed smart contract which programmatically ensures that crowdsourced data is structured, quality, and immutable, and as public/private as you need it to be.
As demonstrated through DCM, Corda is the best platform for the job. Microsoft’s DeCA framework focused on “publicly accessible” models because the gossip protocol isn’t built for privacy while the Ethereum platform can only provide anonymity, hashed data, or off-chain solutions. On Corda however, you could instil your own participation rules which are subjective by default. Without any sort of privacy, there would be no way to secure your machine learning assets on-chain which would leave your application to be used only for non-profit or educational purposes.
Furthermore, storing data on-chain using platforms like Ethereum is extremely expensive and not a great idea for a use case that relies heavily on data sets which could be huge. Machine learning applications on these platforms simply will not scale. Corda states and transactions, on the other hand, can be stored on cloud-hosted databases for a very low cost.
Thanks for reading and feel free to reach out if you are interested in contributing to DCM.
Other References
- DCM Github Repository
- Leveraging blockchain to make machine learning models more accessible
- Decentralized & Collaborative AI on Blockchain
- Scikit Learn Save and Restore Models
- Corda Oracles
- Forever Isn’t Free: The Cost of Storage on a Blockchain Database
- What is the cost to store 1KB, 10KB, 100KB worth of data into the ethereum blockchain?
- Ethereum: A secure decentralised generalised transaction ledger
- Storing on Ethereum. Analyzing the costs