Message Patterns
October 14, 2022
By: Lorcan Wogan, Senior Software Engineer
In recent years, event driven architectures backed by a fault-tolerant and highly-available message bus have become popular. They allow for systems to be designed to share loads across multiple workers, be more easily scaled to handle very large loads and in the event of failures, replay messages that were not completed by faulty processors. We at R3 wanted to harness the power of KAFKA for this very reason. How does one go about writing a library to handle these interactions, which are at the very core of your business processes? What kind of patterns do you require to be part of this library? How should that library be structured? Why abstract these concepts to a library at all?
If N number of developers need to interact with a message bus and there isn’t a shared common library for them to use, then that project will end up N number of solutions, which will inevitably lead to chaos! It makes sense to solve the problem in one place so that developers really don’t have to think about the low level interactions of a message bus. Worrying about operations like polling, committing offsets, sending outputs back to the bus, and replaying failed messages would cause a lot of friction when adding new components. If these concepts are abstracted to a separate library, developers can focus on writing the code that processes input from the bus and produces some sort of output. This maximizes their time and hopefully results in a lot less arguments about whose implementation of the bus interactions was the best!
What is a message pattern?
At this point it’s important to distinguish between a message pattern and a message bus interaction. A bus interaction is a low-level function call to the bus to perform some type of operation such as poll. A message pattern is a higher-level concept, which encapsulates the semantics of how you want your system to interact with the bus. The following is a list of things described by message patterns:
- How many times should failed inputs be retried?
- Should the data processor read from the start of the bus or from the latest offset?
- Does the processor need to read from multiple inputs or a single one?
- Does the processor allow outputs?
- Do we expect a response back for those outputs?
The answer to these questions might be different for different uses cases and so each set of answers represents a different message pattern. One thing you’ll notice is that these questions are bus agnostic. Instead they tell a story of how your component needs to operate. Later on in this article I’ll go through each of the patterns we’ve come up with at R3.
What should the structure look like?
Getting the structure right for a message pattern library is a little more complex than you might think. All you need is some sort of API that exposes the patterns that you’d like to make available and then some implementation module that obeys those contracts, right? Wrong. What if you want to:
- run something simple locally and don’t have enough resources to support a resource-intensive process like KAFKA
- test components simply in a deterministic way, despite your preferred bus being non-deterministic
- run builds on the continuous integration environment that don’t exponentially increase your AWS spend!
To do the above, you’ll need to be able to swap out KAFKA for another message bus such as a DB, or an in-memory solution. When doing this, we still want the bus to behave in the same way for each pattern that has been defined. The best way to do this, is to write a message patterns library that encapsulates the behavior that you want your processors to have with a bus. Then have a separate message bus API to handle the interactions with the bus.
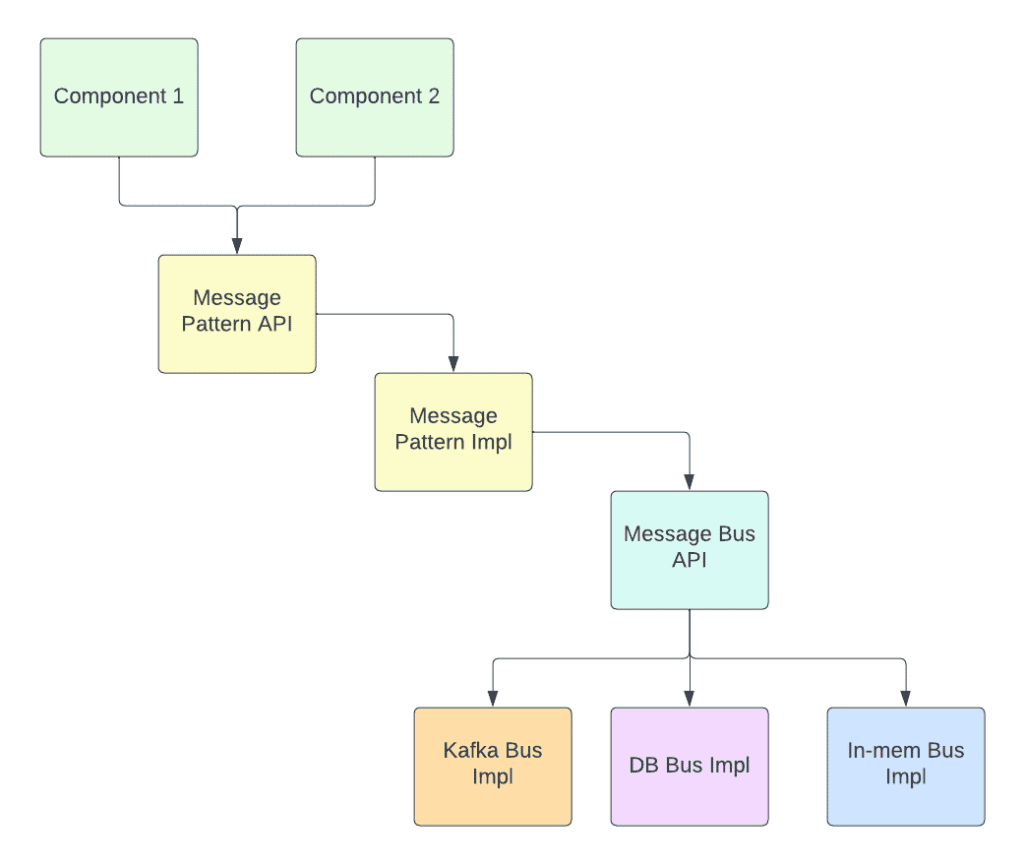
Figure 1. Message Pattern Library Structure
As illustrated in Figure 1, this means that if you want to change the message bus that is used in your environment, you can do so without changing the behavior of your system. With the above structure, a developer can switch out KAFKA for an In-memory solution by changing the runtime dependency of the Message Bus API.
Our messaging patterns
Now that we have a way to structure the project and separate the semantics of bus interactions from the patterns, what does the low-level implementation look like? In R3, we knew our production message bus was going to be KAFKA, so we modelled out the message pattern library using a lot of KAFKA terminology and concepts. This makes it easier for developers to reason about.
At the core of a bus are data packets (records) organized in some way into collections (topics) and a mechanism for parallel processing (partitions). Even though we modelled our generic message pattern library on KAFKA, the concepts can be applied to most message buses.
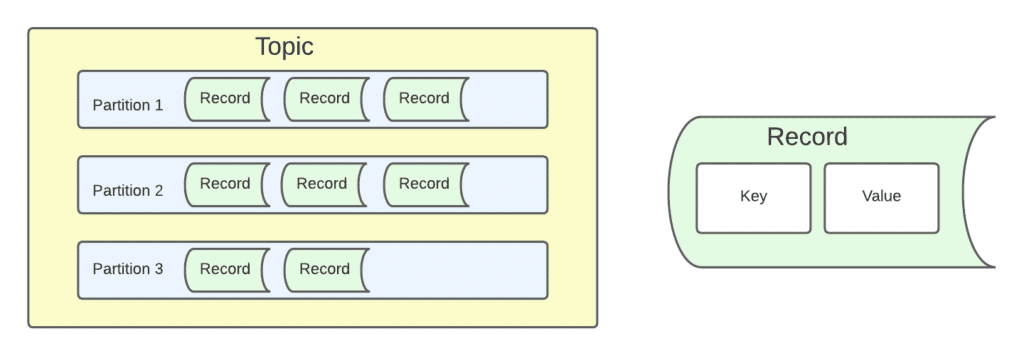
Figure 2. Topic Model
All data packets sent to and from the message bus are wrapped in what we call a record, which is a key value pair. A record is associated with a topic, which is a collection of records. These records can be published, or they can be consumed, processed and outputted to new topics via the patterns. Multiple instances of a pattern can read from a single topic by reading from different partitions. Next we’ll discuss each of the patterns that we’ve built.
Durable pattern
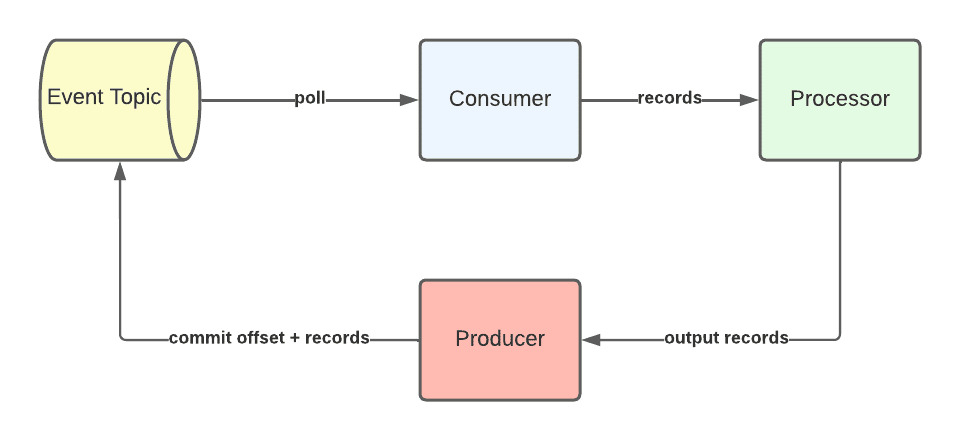
Figure 3. Durable Pattern Overview
Our durable pattern implements a durable message queue, where records are consumed from a topic, beginning with the oldest record. The following points describe the durable pattern.
- Records are processed in batches.
- Each individual record processed can produce zero or many new records of varying types, which are written back to one or more topics.
- Output records are written back to topics as part of a single transaction.
- The consume, process and produce loop is executed atomically. Records are marked as consumed on the source topic in the same transaction as that which outputs the new records.
Our durable pattern aims for ‘exactly-once’ semantics, which as its name suggests means that each message is processed successfully once. If output records fail to write back to the message bus, the consumer will reset to its previous poll position and attempt to consume/process them again.
State and event pattern
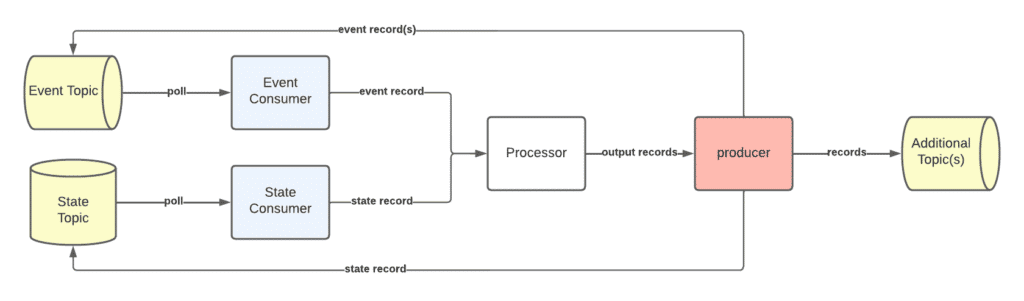
Figure 4. State and Event Pattern Overview
This message pattern is very similar to the durable one. It reads records from an event topic, processes them, and atomically writes back any outputs back to the message bus. The difference here is that events can also have a state associated with them. The state for a given event is stored on a separate topic, however it will always have the same key. When an event is consumed from the event topic, the subscription will retrieve the latest state value for the given key and pass both of these values to the processor.
This pattern is great when you want to store data on the message bus. The state topic acts as a data store and updates to it can be triggered via the event topic. There may be times when a real db is needed to store data. However, if you can get away with using your message bus instead of adding on another piece of infrastructure to your environment, then why not use it? Your build engineers will thank you.
The state and event pattern is probably the most complex pattern that we have, as it must track two different topics. When a partition for an event topic is assigned to the event consumer, the same partition for the state topic is manually assigned to the state consumer and all records from that topic partition must be read before any events are consumed. This ensures that the subscription has the latest state for a given event.
PubSub pattern
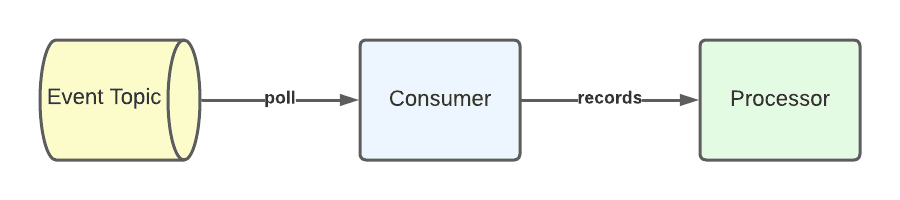
Figure 5. PubSub Pattern Overview
The PubSub pattern, despite being tricky to say out loud, is quite simple. Producers send records via topics to subscribers and if a pattern is not active, then the records will never be received. When a PubSub pattern starts, it will begin consuming new records. No records produced to the topic before the pattern starts will be processed. No records are outputted from the PubSub processors and therefore no records are written back to topics. There are few guarantees given in this pattern. If errors occur, some records may be missed.
This pattern is more suitable when reliable delivery is not a concern, or when old messages should be ignored. If the producer implements resends and the consumer is offline for some time, this can cause a large backlog of messages that need to be processed. This pattern alleviates this issue by only picking up new messages. For example, if you were to implement a heart-beating mechanism to check the health of another component, you wouldn’t care about heartbeats from long ago, as it may already be dead!
Compacted subscription pattern
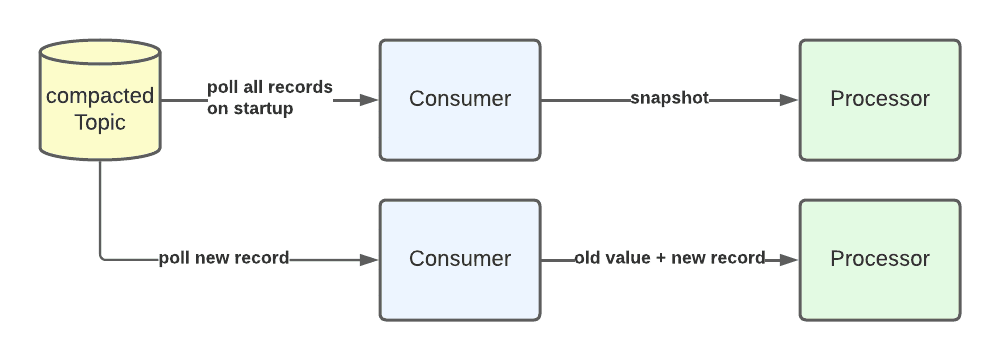
Figure 6. Compacted Subscription Pattern Overview
The compacted pattern is a pattern that consumes records from a topic and produces no outputs. Upon startup of the subscription, all records present on the topic are read, starting with the oldest record. All partitions for the topic are assigned to the consumer to ensure that no records are missed. An in-memory map of the latest values for each key is constructed, which is referred to as the snapshot. This map is then passed to the compacted processor to be processed.
Any new records consumed from the topic after this point are read individually and passed to the processor, along with the previous value for the same key. This pattern is useful for storing data on the message bus as key value pairs, where only the latest values of the keys are of importance. Configuration data is one example where we use this pattern.
RPC pattern
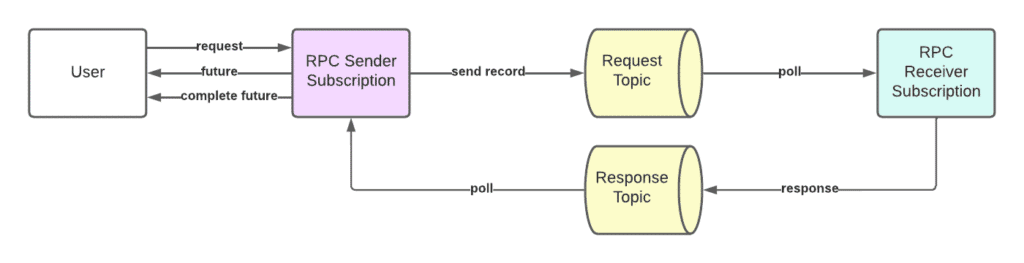
Figure 7. RPC Pattern Overview
The RPC pattern allows for a record to be sent to the message bus on a specific partition of a topic, a separate process to receive this record, process it, and then send it back a response record on the same partition of a separate response topic. In this way we can make requests to remote processes and receive back a response, just like a normal remote procedure call.
The sender is given a future to track the progress of the request, but message delivery for this pattern is not reliable. The receiver side reads from the latest messages on the sender topic, which means that if there is downtime on the receiver side, any messages sent during that time will not be processed. The sender must have some way of retrying requests if they fail.
Message buses are usually used to process streams of data and are not naturally appropriate for an RPC pattern. Given that all other communication in Corda’s deployment ecosystem is done through the message bus, we decided to use it for this pattern too. This also means that RPC calls can enjoy the benefits provided by message buses like KAFKA, such as being highly-available and scalable.
Using the message bus for this pattern does not come without its challenges. We must ensure that the sender outputs the record onto the same partition and is listening on the correct partition and topic for the response.
Closing thoughts
When most developers in your company are required to interact with a component like a message bus to write core business logic, it makes sense to abstract away this logic behind some easy-to-use APIs. It’s important to think through the various use cases that developers will require from an early stage, in order to identify patterns and construct APIs that can be used and extended over time to address developers needs. It’s never possible to think of all possible ways that a developer may want to interact with a message bus, but new patterns can always be added over time.
Hiding the message bus behind an API means that different message buses can be used for different use cases. A production-level message bus such as KAFKA can be switched out for an in-memory db such as HSQL for use in unit tests for local development. In the future, if customers would prefer to use a bus other than KAFKA, a new message bus implementation can be more easily added, given that the patterns are well-defined.
There may also be opportunities in the future to use different tech stacks for different use cases. A key value store such as REDIS may be more appropriate for large data objects, rather than a message bus for the compacted pattern. Also, a traditional database may be more suited for storing state in the state and event pattern. However for the moment, a message bus achieves all our goals and hiding its usage behind our patterns API means that we can easily update it in the future.